The Goal of this project is to download all Craigs list listings by user and dealer.
The first step is to collect data.
The user decides what section of the website to be scrapped and how many pages or listings to be downloaded.
Once you enter this information the scrapper will download all the information and store them in a Database for you.
This can be used for further analysing.
We used the programming language python for this project.
Craig’s list features owners and dealers to sell items in their site. Our final database will also have a section whether this itemis listed by owner or dealer.
The libraries we use are urllib, Sqlite3, requests, Beautifulsoup ,re and operator.
The program is two stage
Stage 1: Individual page link down-loader.
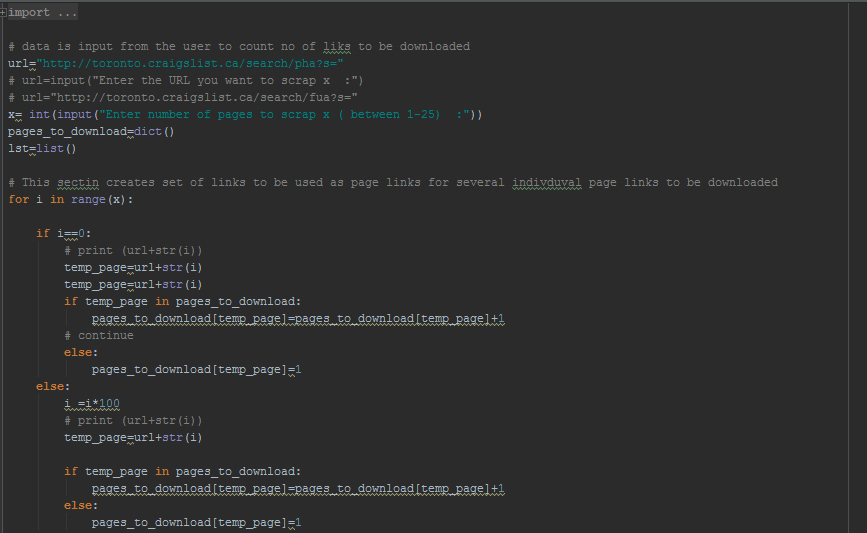
Stage 2 : Individual page info down-loader.
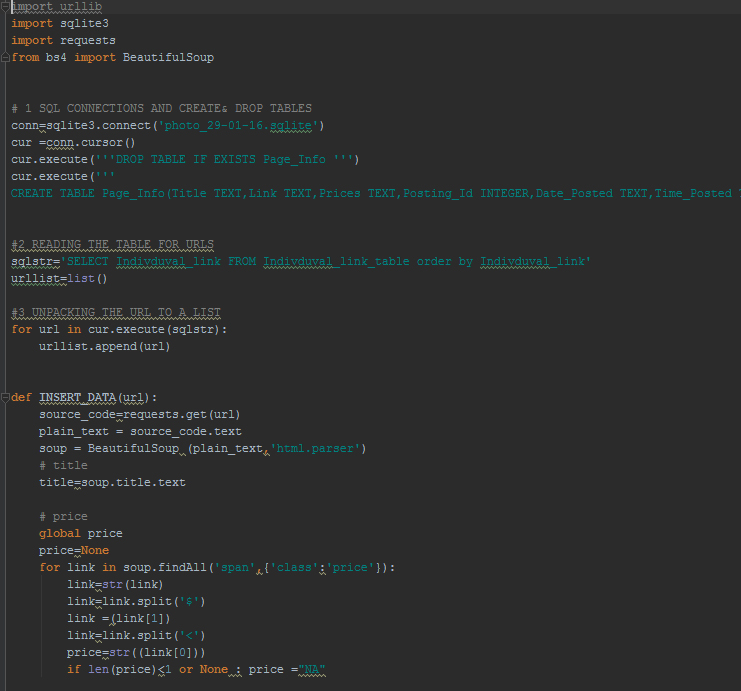
Once the we run these two programs, Python creates a database with all the necessary information.
3 tables are created
1.Total page link table.
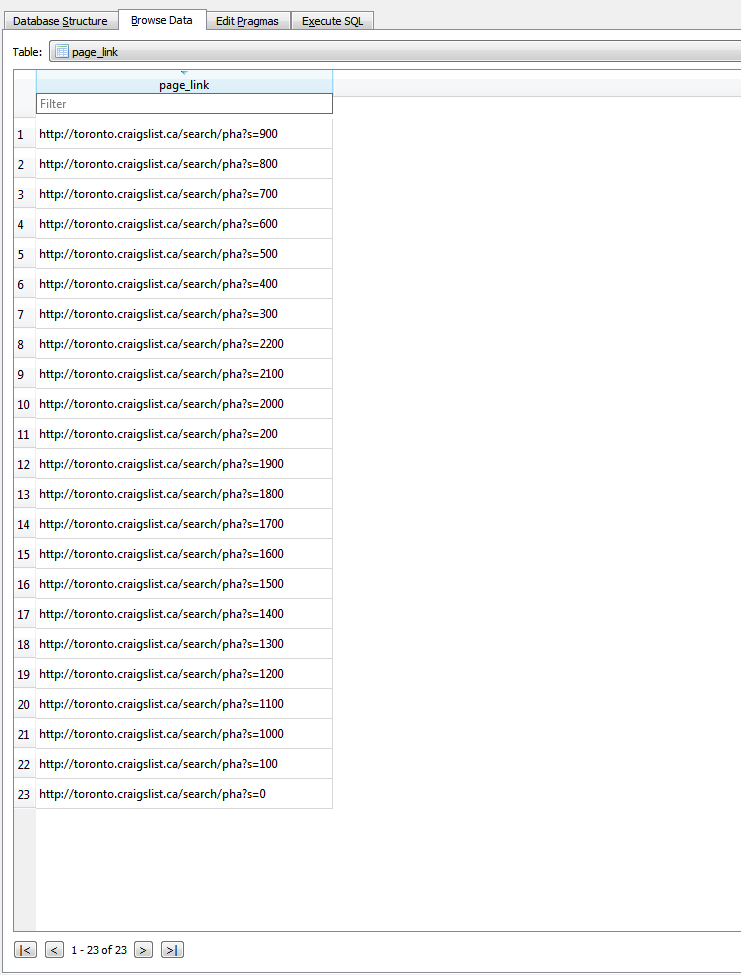
2.Individual links for each page in a table.
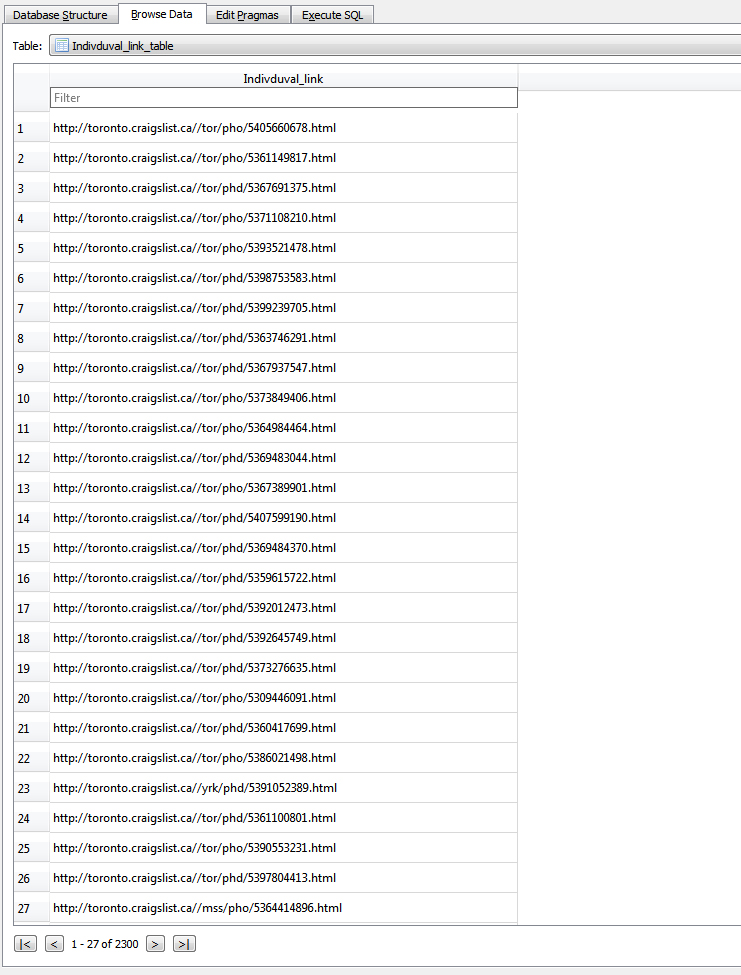
3.Final information of the listing.
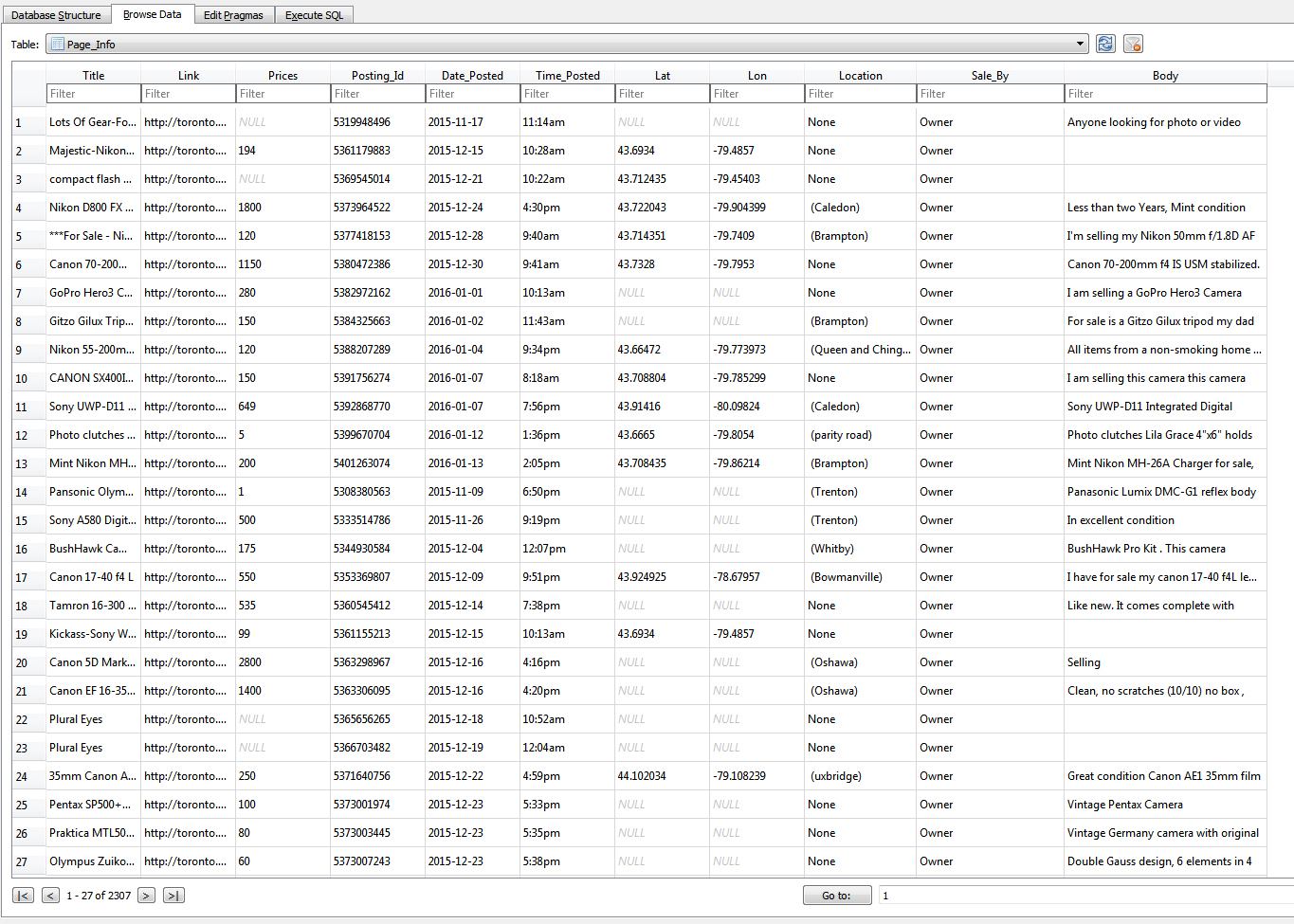
We finally generated 2500 listings per run.










Recent Comments