
Grab the latest news and commentary about Hadoop in this week’s Hadoop Happenings. This week commentary focused on Hadoop in action. Walmart discussed its plans for Hadoop, and an article on CIO.com discussed Hadoop’s impact on the insurance industry. See the full stories below..
It’s amazing the growth Apache Hadoop and the extended ecosystem has had in the last 10 years. I read through Owen’s “Ten Years of Herding Elephants” blog and downloaded the early docker image of his first patch. It reminded me of the days it took me to do my first Hadoop install and the effort it was to learn the Java MapReduce basics to understand the infamous WordCount example. How far have we come? Let’s go through a basic Hadoop tutorial today on the Sandbox today to see all the progress we’ve made.
In addition, let’s take a closer look at the six labs in the intro to Hadoop tutorial and take a retrospective on how things have changed. The six labs in the tutorial are:
- Lab 1 – Loading Data into HDFS
- Lab 2 – Hive and Data ETL
- Lab 3 – Pig Risk Factor Analysis
- Lab 4 – Spark Risk Factor Analysis
- Lab 5 – Data Reporting
- Lab 6 – Data Reporting With Zeppelin
Before I begin going through the labs, I have to give a special shout out to the Sandbox. The Sandbox provides an easy way for users to get started with distributed data platform on their personal machines via Virtual Machines or the cloud. It provides a pre-installed, pre-configured and optimized single node environment for Hadoop that stays current with the evolving ecosystem.
Loading Data into HDFS
After installing and setting up Hadoop, the next challenge developers tend to run into is getting data into Hadoop.
BEFORE
In the beginning Hadoop was a collection of services and there was no User Interface. When you wanted to load data into Hadoop, you had to learn Hadoop and HDFS commands, and go to the command line.

NOW
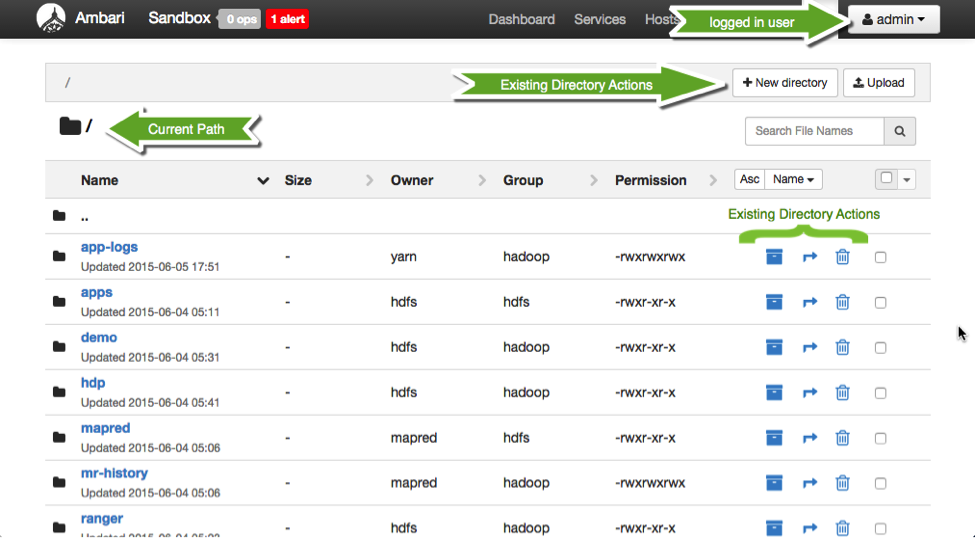
Hadoop has a modern administrative UI with Ambari. Ambari provides a collection of tools for administering Hadoop and also a collection of Ambari User Views like the Ambari HDFS Files View.
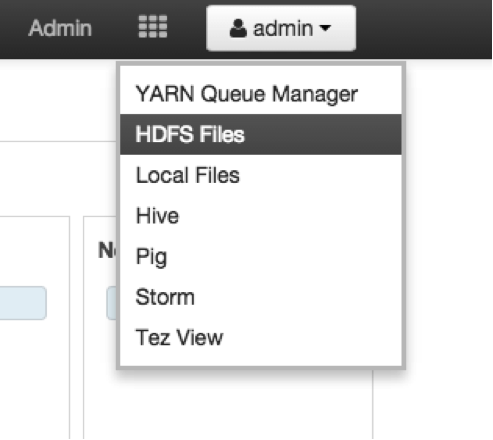
This view allow users to explore and manipulate data in Hadoop Distributed File System (HDFS). You can easily perform many common operations like loading data, creating and removing directories and moving data.
Hive and Data ETL
After you get some data into Hadoop, the next thing a developer might try is to explore the data.
BEFORE
In the early Hadoop days, you had only one option to do data processing, which included writing a Java MapReduce program. MapReduce is a powerful tool that opened up many new opportunities to do data processing, but there was a limited amount of developers that knew it.
NOW
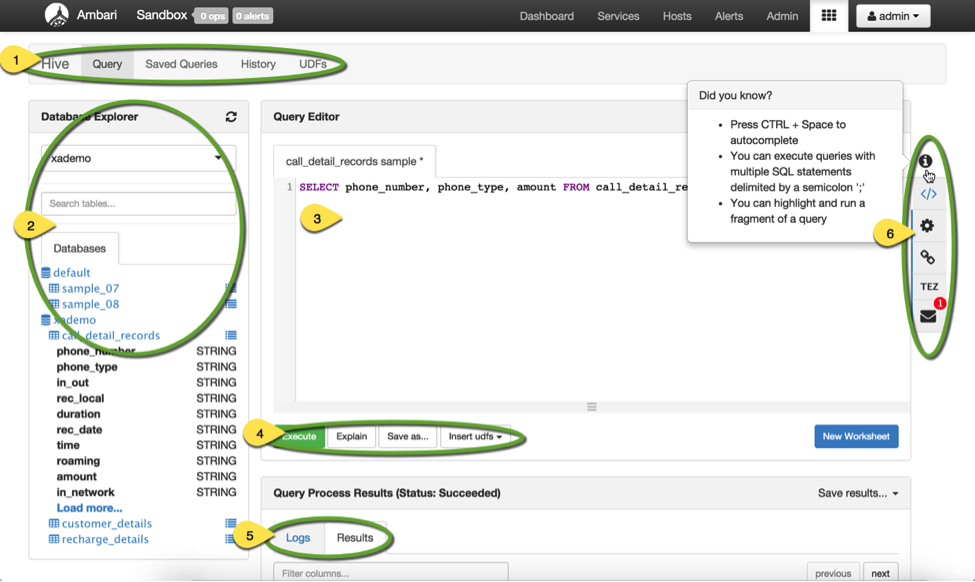
The lingua franca for data processing is SQL. Facebook lead the charge of bringing SQL access to Hadoop with Hive. If you are a SQL person trying to learn Hadoop, you can leverage your SQL skills to start exploring data. Additionally, you can use the Ambari Hive View to write queries, see results and tune them.










Recent Comments